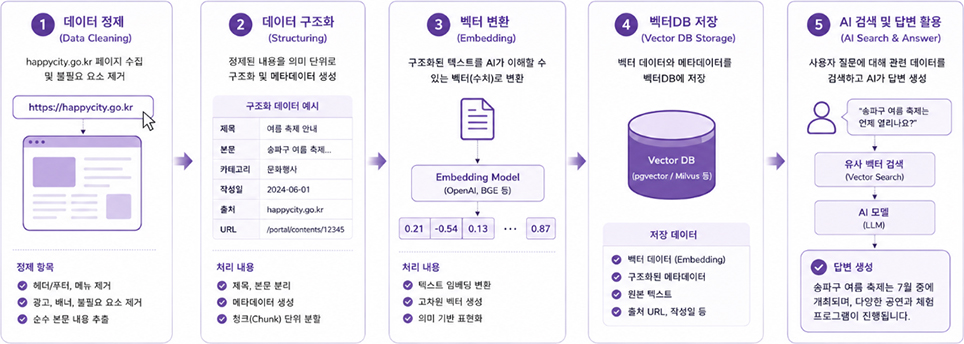
크롤링 단계
웹사이트의 정보를 자동으로 수집하고 AI가 학습할 수 있도록 정리하는 4단계 과정을 소개합니다.
-
1탐색 (Exploration)
웹페이지를 찾아
탐색합니다.
-
2선별 (Selection)
필요한 정보만 골라
정리합니다.
-
3저장 (Storage)
선별된 데이터를
체계적으로 저장합니다.
-
4처리 (Processing)
AI가 이해할 수 있도록
데이터를 변환합니다.
각 단계 자세히 보기
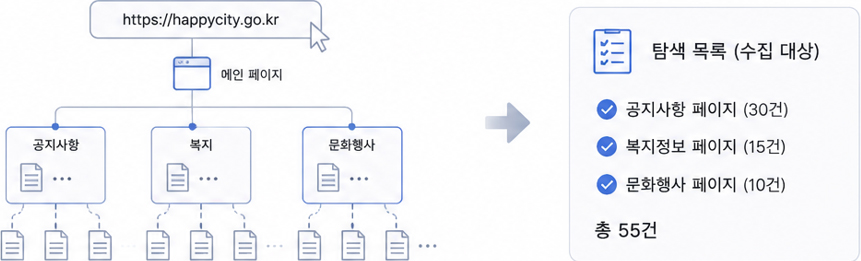
1탐색 (Exploration)
웹페이지를 찾아 탐색합니다.
| 설명 | 예시 |
|---|---|
| 사용자가 설정한 URL을 기준으로 탐색을 시작합니다. | https://happycity.go.kr을 기준으로 탐색 시작 |
| 웹페이지를 분석하여 링크, 이미지 등 주요 정보를 파악합니다. | 메인 페이지에서 ‘공지사항’, ‘복지’ 등 메뉴 확인 |
| 페이지 내 링크를 따라 하위 페이지까지 확장 탐색합니다. | ‘공지사항’ 클릭 → 개별 게시글 페이지까지 이동 |
| 설정한 웹사이트 또는 특정 폴더 범위 내에서만 탐색합니다. | happycity.go.kr 내부 페이지만 탐색하며, 외부 사이트는 제외 |
| 중복된 페이지는 제외하고, 설정한 깊이까지만 탐색합니다. | 같은 게시글은 한 번만 수집하고, 2단계까지만 탐색 |
| 탐색한 페이지를 정리해 수집 대상 목록을 생성합니다. | 공지사항 30건, 복지 15건 등 수집 대상이 목록으로 정리 |
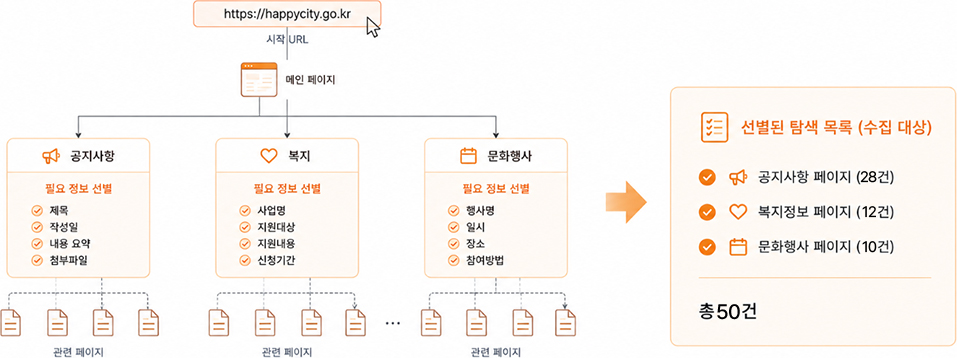
2선별 (Selection)
필요한 정보만 골라 정리하는 단계입니다.
| 설명 | 예시 |
|---|---|
| 수집된 페이지 중 필요한 정보만 골라냅니다. | 공지사항, 복지정보, 문화행사 등 주요 페이지 확인 |
| 중복된 페이지는 자동으로 제외합니다. | 같은 공지글이 여러 경로로 수집된 경우 1건만 유지 |
| 내용이 동일하거나 비슷한 페이지는 하나만 남깁니다. | 제목이나 내용이 거의 동일한 게시글은 하나로 통합 |
| 불필요한 페이지는 제외합니다. | 로그인, 관리자 페이지 제외 |
| 중복된 페이지는 제외하고, 설정한 깊이까지만 탐색합니다. | 같은 게시글은 한 번만 수집하고, 2단계까지만 탐색 |
| 뉴스, 게시글 등 의미 있는 콘텐츠만 선별합니다. | 공지사항, 복지 안내, 행사 정보 등 주요 정보만 유지 |
| 정리된 페이지 목록을 생성합니다. | 공지사항 28건, 복지 12건, 문화행사 10건으로 정리 |
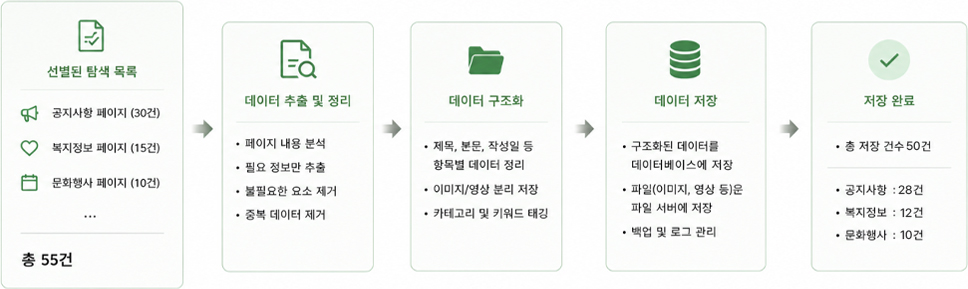
3저장 (Storage)
선별된 데이터를 저장하는 단계입니다.
| 설명 | 예시 |
|---|---|
| 웹페이지의 내용을 분석하여 필요한 정보만 추출합니다. | happycity.kr 공지사항 페이지에서 제목,본문 내용 가져오기 |
| 상단 메뉴, 하단 정보, 광고 등 불필요한 요소는 제외합니다. | 헤더 메뉴, 푸터 저작권 영역 제거 |
| 긴 내용을 문단 단위로 나누어 저장합니다. | 공지사항 본문을 여러 문단으로 분리 |
| 이미지와 영상 등 미디어 데이터를 함께 정리합니다. | 첨부 이미지 저장, 영상에서 자막 정보 추출 |
| 제목, 요약, 키워드 등 데이터를 설명하는 정보를 생성합니다. | 제목 “여름 축제 안내”, 키워드 “행사, 문화” 생성 |
| 뉴스, 게시글 등 의미 있는 콘텐츠만 선별합니다. | 공지사항, 복지 안내, 행사 정보 등 주요 정보만 유지 |
| 데이터를 일정한 형식으로 구조화하여 저장합니다. | 제목 / 날짜 / 내용 / 이미지 형태로 정리 |
4처리 (Processing)
AI가 이해할 수 있도록 데이터를 변환하는 단계입니다.
| 설명 | 예시 |
|---|---|
| 저장된 데이터를 AI가 이해할 수 있는 형태로 학습합니다. | happycity.kr공지사항 내용을 AI가 읽고 의미를 파악 |
| 데이터를 검색이 가능하도록 벡터 형태로 변환합니다. | “여름 행사 안내” 글을 숫자 데이터(벡터)로 변환 |
| 변환된 데이터를 벡터 데이터베이스에 저장하고 관리합니다. | 공지사항 데이터를 데이터베이스에 저장하여 빠르게 검색 가능하도록 구성 |
| 다양한 언어로 번역하여 함께 저장합니다. | 공지사항 내용을 영어, 중국어 등으로 자동 번역 후 저장 |
| 데이터를 AI가 활용할 수 있도록 정리합니다. | 사용자가 질문하면 관련 공지사항을 바로 찾아서 답변 가능 |